Dbs101_unit6
Unit 6: Indexing, Query Processing, and Optimization in Database Systems
After completing the foundational units on database design and the Entity-Relationship Model, I was eager to explore how databases efficiently retrieve and process data. Unit 6, covering Indexing, Query Processing, and Optimization, provided deep insights into these critical aspects. Here’s a detailed account of my learning journey.
Previous Understanding of Indexing and Query Processing
Before this unit:
- Thought indexes were simple lookup tables
- Assumed databases magically fetched data without understanding the process
- Considered optimization as something only DBAs worried about
Key Learnings from Unit 6
Indexing
Indexes are like the table of contents in a book—they help the database quickly locate data.
Types of Indexes:
- Ordered Indices: Values stored in sorted order
- Hashed Indices: Uses hash functions to distribute values
- Dense vs. Sparse:
- Dense: Entry for every search key
- Sparse: Entries only for some keys
B-Tree Family:
- B-Tree: Self-balancing tree with multiple keys/children per node
- B+ Tree: Only leaf nodes store data pointers (ideal for range queries)
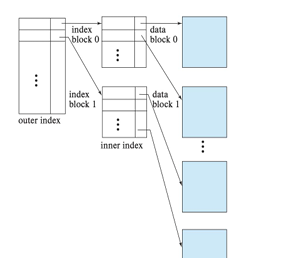
Multilevel Indexing:
- Used when indexes don’t fit in memory
- Outer index (memory) points to inner index blocks (disk)
Query Processing
Three main steps:
- Parsing and Translation:
1
SELECT * FROM employees WHERE salary > 50000 → σ_salary>50000(employees)
- Optimization:
Evaluates multiple execution plans
Uses pipelining/materialization techniques
- Evaluation:
Executes chosen plan via query engine
Query Optimization
Key concepts:
Cost Estimation:
Based on disk I/O, CPU, memory
Example: Join costs vary by algorithm (nested loop vs hash join)
Transformation Rules:
Commutative property: σ_θ1(σ_θ2(E)) ≡ σ_θ2(σ_θ1(E))
Join commutativity: E1 ⋈ E2 ≡ E2 ⋈ E1
Join Ordering:
Uses dynamic programming
Example: (R JOIN S) JOIN T often better than (S JOIN T) JOIN R
Practical Application
Creating Indexes
1
2
3
4
5
-- Dense index
CREATE INDEX employees_idx ON employees (emp_id);
-- Sparse index
CREATE INDEX employees_sparse_idx ON employees (salary) WITH (fillfactor=100);
Analyzing Queries
1
EXPLAIN ANALYZE SELECT * FROM employees WHERE emp_id = 12345;
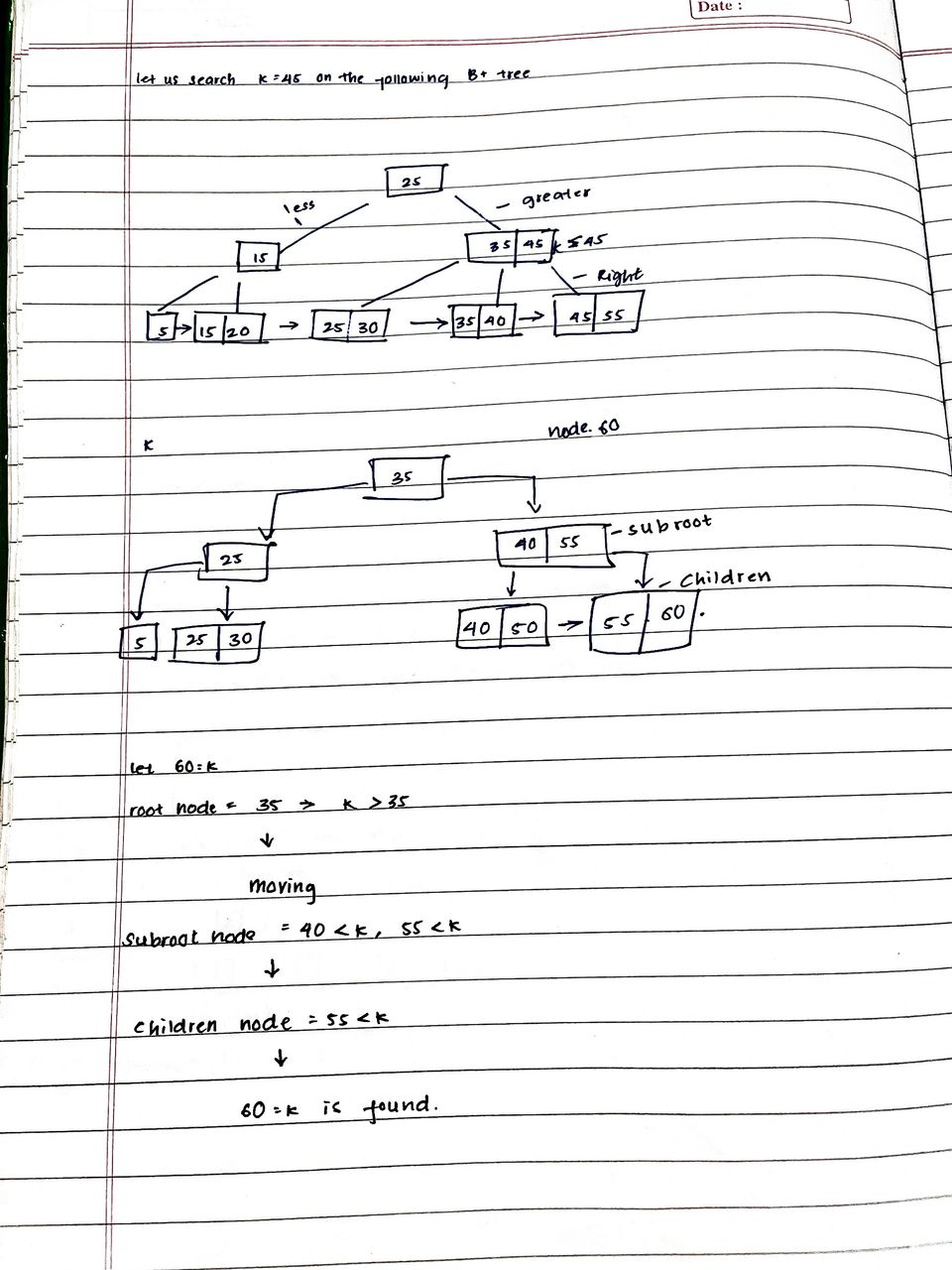
Homework
Conclusion
This unit transformed my understanding of:
How indexes actually work (B+ Trees are brilliant!)
The systematic process behind query execution
The science of optimization beyond “magic”
These skills are directly applicable to building high-performance databases.
Reflection
From clueless about query plans to:
Confidently creating optimal indexes
Understanding execution paths
Calculating operation costs
Excited to apply these in real projects and continue learning.